Structural decomposition, organization, element naming, component naming, and assembly naming are the essential activities of problem analysis and software design. While these activites form the heart of software development, they still have received insufficient address in software development literature.
Please Note! While these conventions are phrased as rules (with shoulds), these conventions are currently rather ad hoc and will eventually need to be organized and elaborated upon. They are currently intended solely to serve as discussion points rather than as accepted rules.
individual, team, group, community
natural conceptual modeling and natural naming as foundation practices
branding, open or close source, community process,
communities specify, develop, and use platforms
groups (SIGs) specify, develop, and use libraries
teams specify, develop, and use packages
developers specify, develop and use types and classes
1.0 Whenever possible, organize components into coherent, clearly defined and distinctly named packages.
The object-oriented approach to software design tends to produce large libraries with many components, including both types (interfaces) and classes. Object-oriented design has a few basic organizational and metaphoric themes that adherents use repeatedly and extensively. As a consequence, software developers who use the object-oriented approach will often use similar conceptual models, similar software metaphors, and similar component naming conventions in their designs.
Substantial object systems often integrate components from different libraries, which are often created by independent software developers and organizations. However, given the similarities in design approach, metaphor usage, and naming conventions, the likelihood that these libraries will contain components with conflicting names increases dramatically. So, software developers need means whereby they can distinguish components with the same names from each other, both to prevent naming conflicts and to better organize the components they publish and share with other developers.
Programming language mechanisms for resolving component naming conflicts have historically been given the term namespaces. Namespaces are essentially named packages of named components. Each named component within a named library can be uniquely identified by combining the library name with the component name, thus producing a fully qualified component name.
The original Smalltalk language and development environments had no namespace mechanism with which to separate classes into distinct packages. Collectively, these original Smalltalk systems offer good examples of the problems that arose without a namespace mechanism. Using and reusing independently developed (and third-party) Smalltalk libraries often led to integration problems as class naming conflicts arose. So, Smalltalk developers often had to adopt some kind of extended class naming convention and thus contaminate their class names, typically with some class name prefix or suffix to identify and distinguish different package affinities in their class names. Some of the commercially available Smalltalk systems have since resolved this problem with proprietary extensions.
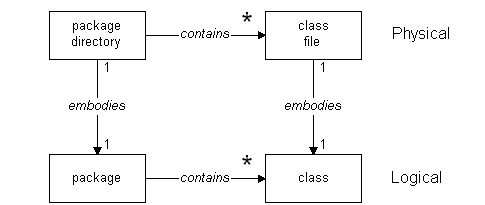
On the other hand, Ada, C++ and Java offer standard language mechanisms to separate components into distinct packages. C++ directly supports the definition and use of namespaces. C++ namespaces offer a logical way to organize and separate C++ class definitions, but C++ namespaces have no physical analog. Java offers packages, which also provide separate class namespaces. However, Java packages also provide a physical analog: package directories organize Java class files within a file system. The following diagram offers a summary of these relationships and logical - physical analogs.
Java packages also participate in the Java access control and security models.1 Packages may be sealed to prevent the external introduction of new package members via inclusion in the CLASSPATH. However, a detailed discussion of these mechanisms and their design implications is beyond the scope of this current consideration.
1.1 Organize server interfaces, server implementations and standard client implementations into separate packages.
Packages provide means for component distinction and separation, organization and categorization. Their primary uses in design include:
- distinguishing and categorizing named entities (namespaces)
- separating interfaces (types) from their implementations
- managing dependencies between classes (and libraries)
- organizing types and classes into subsystems
This last usage offers perhaps the most compelling motivation behind the Java package mechanism, as the object-oriented approach to software design often results in organizations of collaborating classes into coherent subsystems. As noted in Designing Object-Oriented Software,2
There is no conceptual difference between the responsibilities of a class, a subsystem of classes, and even an application; it is simply a matter of scale, and the amount of richness and detail in your model.Each subsystem usually offers an interface, often via a Façade3 abstraction. When a programming language supports the definition of types apart from classes (as Java does with its interface definition mechanism), separating the subsystem interface types from their implementation classes will usually improve the subsystem design. Separately defined interface types help clarify the service contract between a server subsystem and its clients, and they also provide a stable abstraction for both the subsystem clients and the implementation classes.
Given that a subsystem has separate interface types defined, these can be organized into their own library. For example, the separated types are often offered in a base package from which other packages are extended in Java. A typical package organization for a Java subsystem might look something like this:
com.acme
.face
.client
.imp
.testIn this example,
- the face package contains the subsystem interface types, and any attendant exception class(es) introduced by those types,
- the face.imp package contains the subsystem implementation classes,
- the face.client package contains any standard wrapper classes or remote client proxy classes,
- the face.test package contains the standard unit test and functional test harnesses.
Organizing packages with a convention like this supports the clean separation of the components needed by clients from those needed by the server, and the eventual elimination of the test harnesses in deployments. For example,
- each distributed client receives the face + face.client packages
- each distributed server receives the face + face.imp packages
These different component configurations are usually deployed in distinct archive files (separate ZIPs, JARs, or WAR + EAR pairs).
1.1 Follow the general component package naming and organization conventions of the relevant developer communities.
Software developers rarely work alone any more. Most significant software products require teams. Even when a team is small, it needs some conventions. Many naming conventions are cultural, applicable within a given developer community. Development teams need to agree on the conventions that will support their ability to collaborate and share concepts and code effectively.
1.2 A component package name should reveal the overall theme and purpose of the components it contains.
With large component libraries, locating components for reuse becomes a daily development chore. The package names play an important role in helping developers discover useful components.
1.3 A package name may use abbreviations, but abbreviations that suggest the full name are preferable.
Short package names are preferable to long ones, especially when each name is part of a larger composite name, as with Java package names. However, abbreviations formed from word intitals offer little or no intelligibility to the uninitiated. Poorly chosen abbreviations generally obscure rather than reveal the intended theme of a library. The Java platform uses many abbreviated package names, but the names that use word initals are generally limited to well known and often used services. The following table offers some examples:
|
Clearly, the abbreviations formed from word initials are more obscure than those formed by word truncation. However, SQL is an industry standard, and all programming languages must somehow support I/O. So, these abbreviations will generally be recognized by developers. However, only those who study the associated tutorials and doucmentation will likely recognize AWT for what it is. Perhaps facekit would have been a better choice (derived from interface toolkit). Of course, many of these choices will depend on individual style and team dynamics, but some senstivity to the issue and consideration of both the local developer culture and the larger developer community will help imrove the intelligibility of package names.
1.4. Avoid cyclic dependencies between packages.
Each package should be a separately compilable unit with clean separation from other packages and with a clean dependency graph. Package dependencies should be definable by a directed acyclic graph (DAG). A cyclic dependency between classes from different packages (whether direct or indirect) often indicates either a poor or an immature design. However, a close cyclic dependency between a pair of classes may also simply reveal an extremely intimate relationship between collaborators. Where stable intimacy exists between a pair of classes, it should be honored by co-locating the intimate collaborators within the same package, thus eliminating the cyclic dependency between packages. Intimate collaboration between classes may be honorable, but should never exceed the bounds of a single package.
Instance variables are an optimization (often the first). Instance variables cache information, but the choice of knowledge ownership within an object graph may change over time as a design matures. However, the likelihood that the original owner (or its clients) will still need to access the information will remain high, even after refactoring to move the cache somewhere else.
If you have some named objects, give the object class some metaclass (or static) protocol for looking up its instances using their names.
"Smalltalk example"
exampleName := 'example.name'.
example := Example named: exampleName.// Java example
String exampleName = "example.name";
Example example = Example.named( exampleName );
If you have some uniquely identifiable objects, give their class some metaclass (or static) protocol for looking up its instances using their unique identifiers.
"Smalltalk example"
exampleId := 1234567890.
example := Example from: exampleId.// Java example
long exampleId = 1234567890;
Example example = Example.from( exampleId );